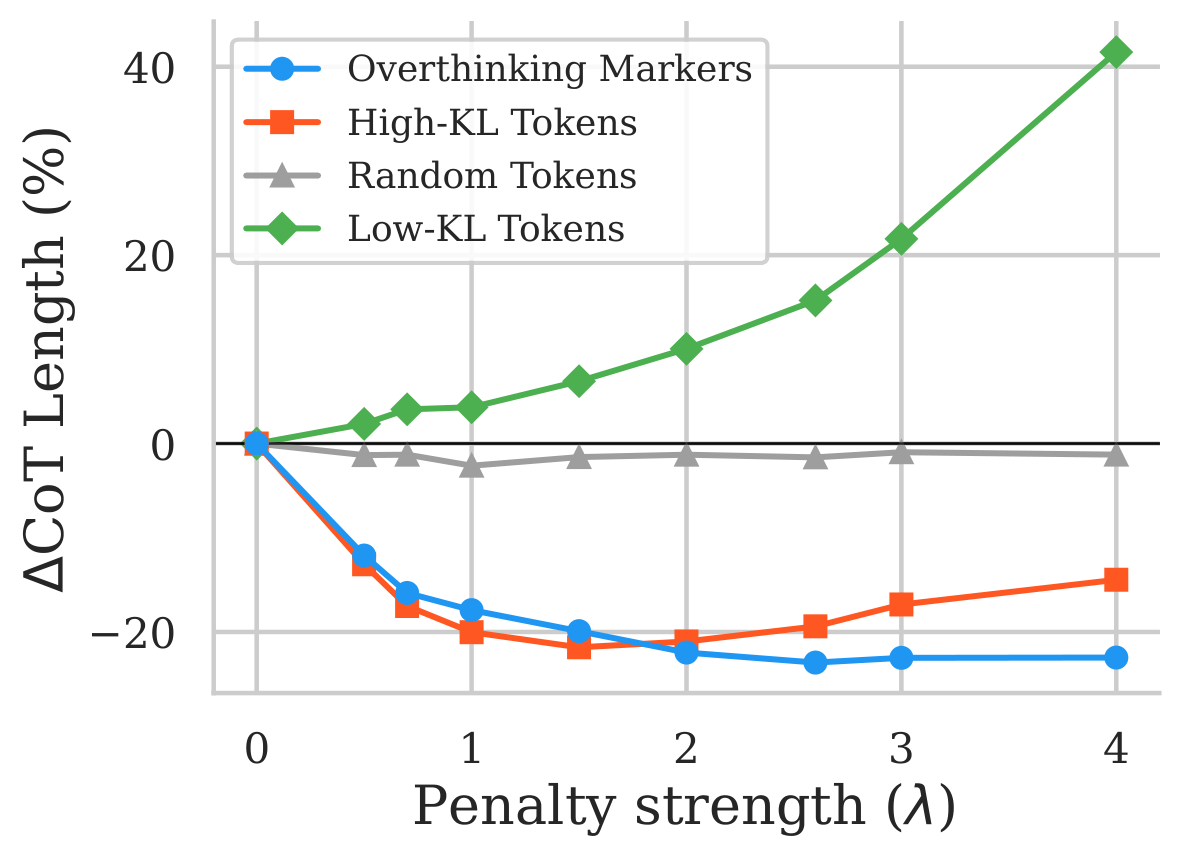
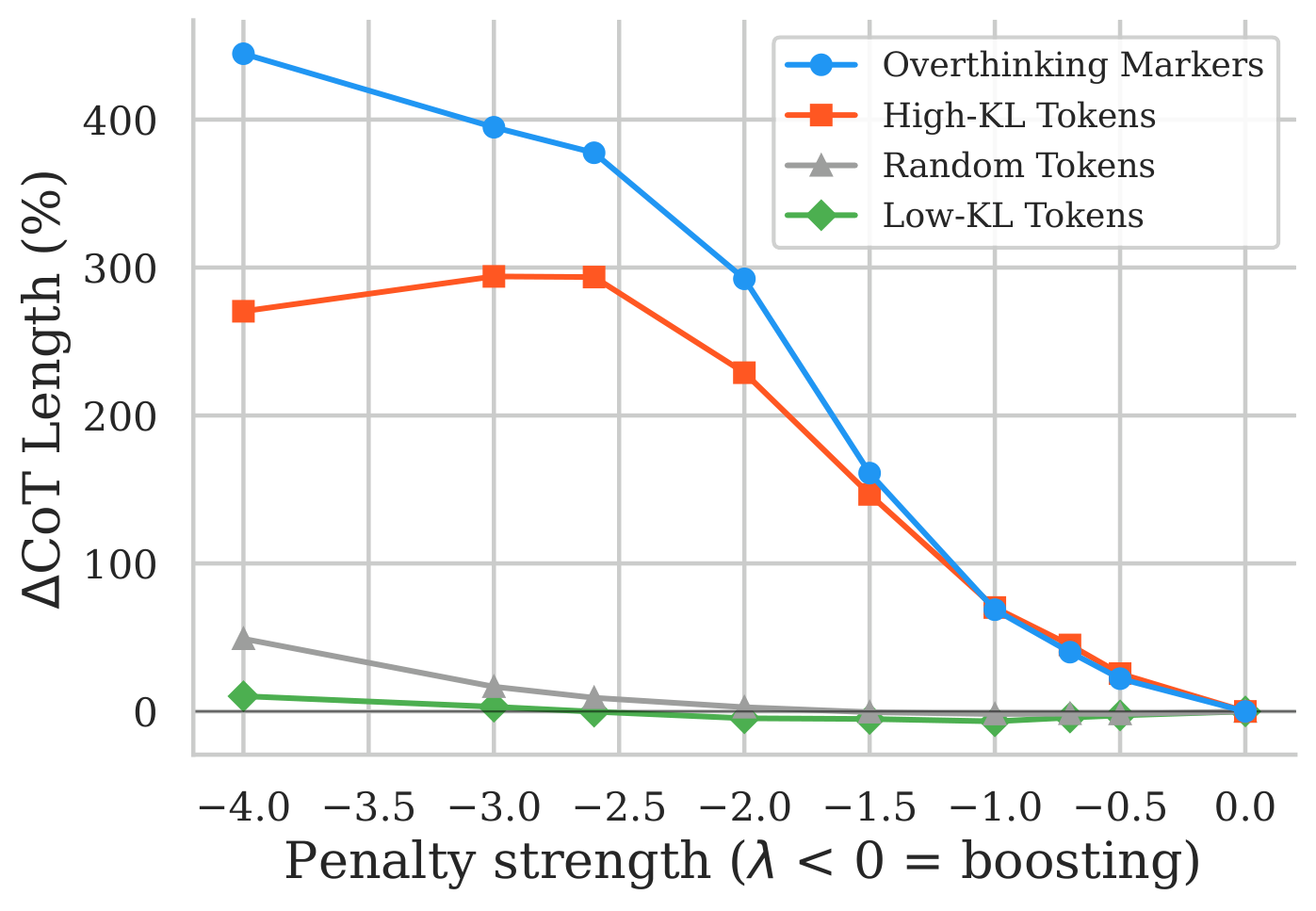
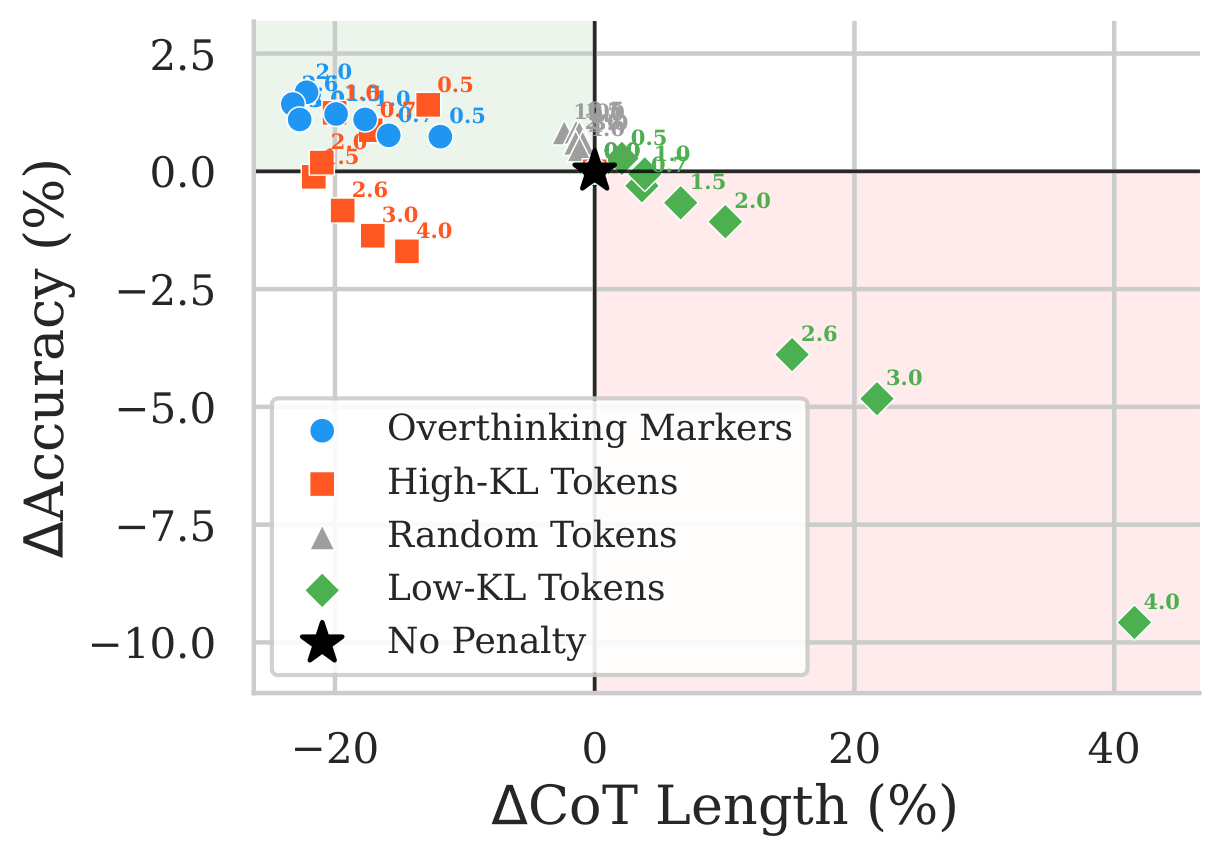
Accuracy drops while CoT length increases under PTQ
We evaluate five reasoning specialized models spanning 1.5B to 32B parameters (DeepSeek-R1-Distill-Qwen 1.5B, 7B, 14B, DeepSeek-R1-Distill-Llama 8B, and QwQ-32B), three PTQ methods (GPTQ, AWQ, FlatQuant), and five benchmarks across mathematics, coding, and science (AIME-120, MATH-500, GSM8K, GPQA-Diamond, LiveCodeBench). Mild quantization (FlatQuant W8A8KV8, 4 bit weight only AWQ and GPTQ) is largely benign: accuracy and CoT length both stay close to the BF16 baseline. As precision drops further, accuracy and reasoning efficiency degrade together. The figure below shows this for DeepSeek-R1-Distill-Qwen-1.5B on MATH-500, and how the overthinking penalty shifts the accuracy versus reasoning cost tradeoff.
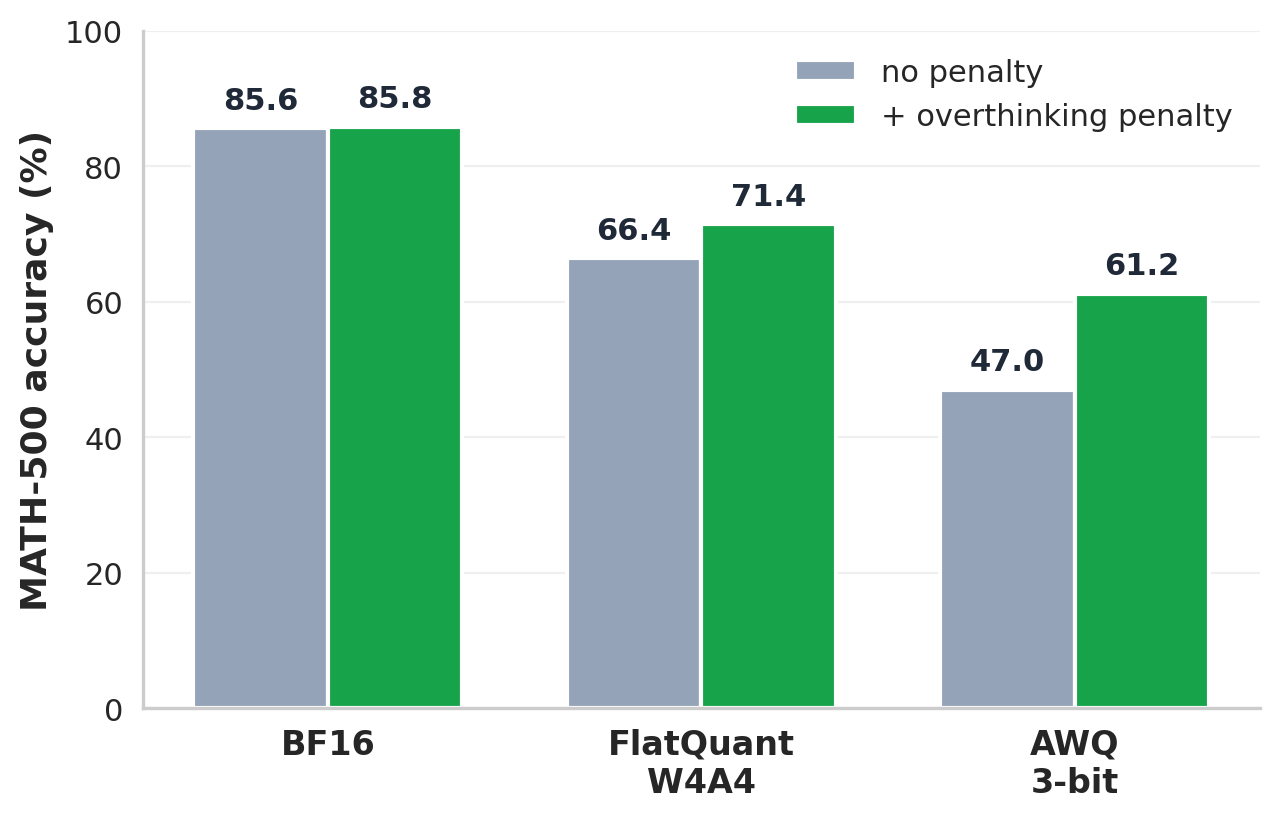
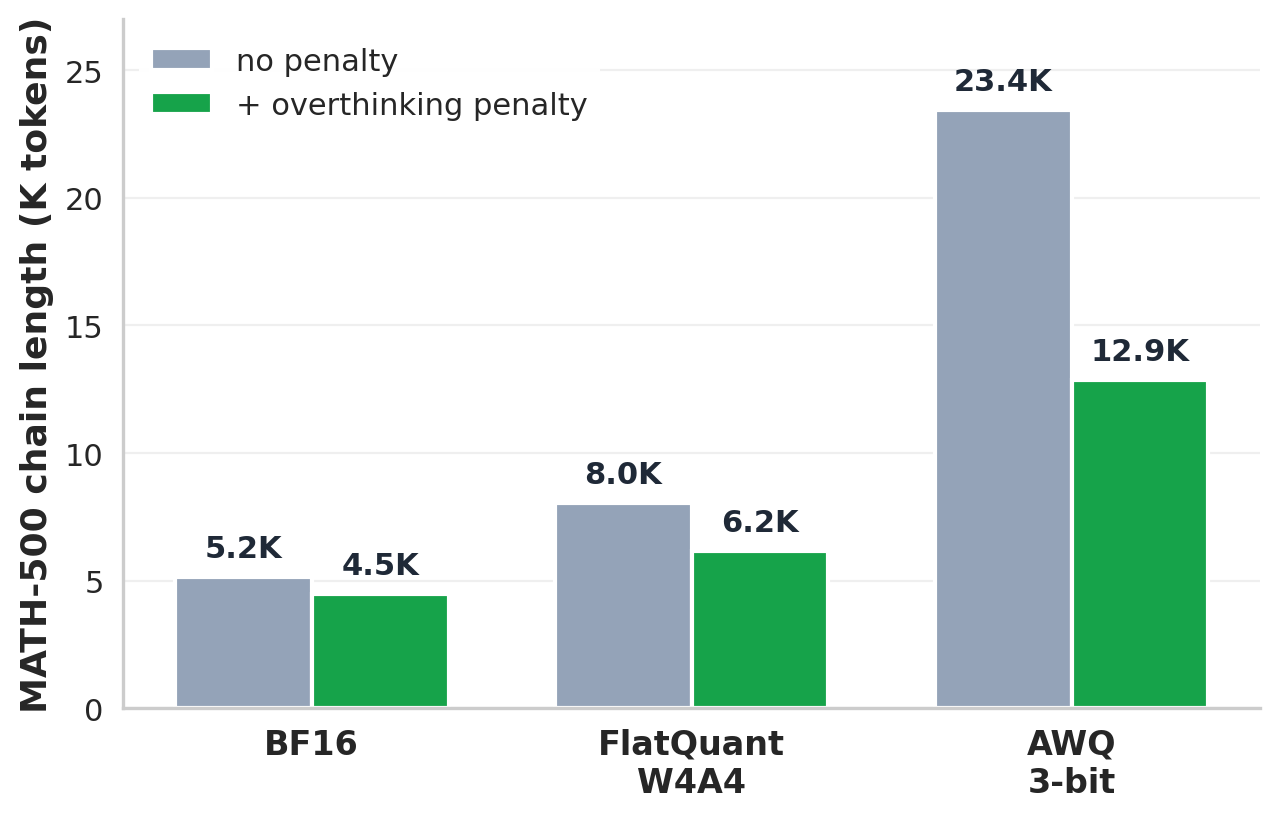
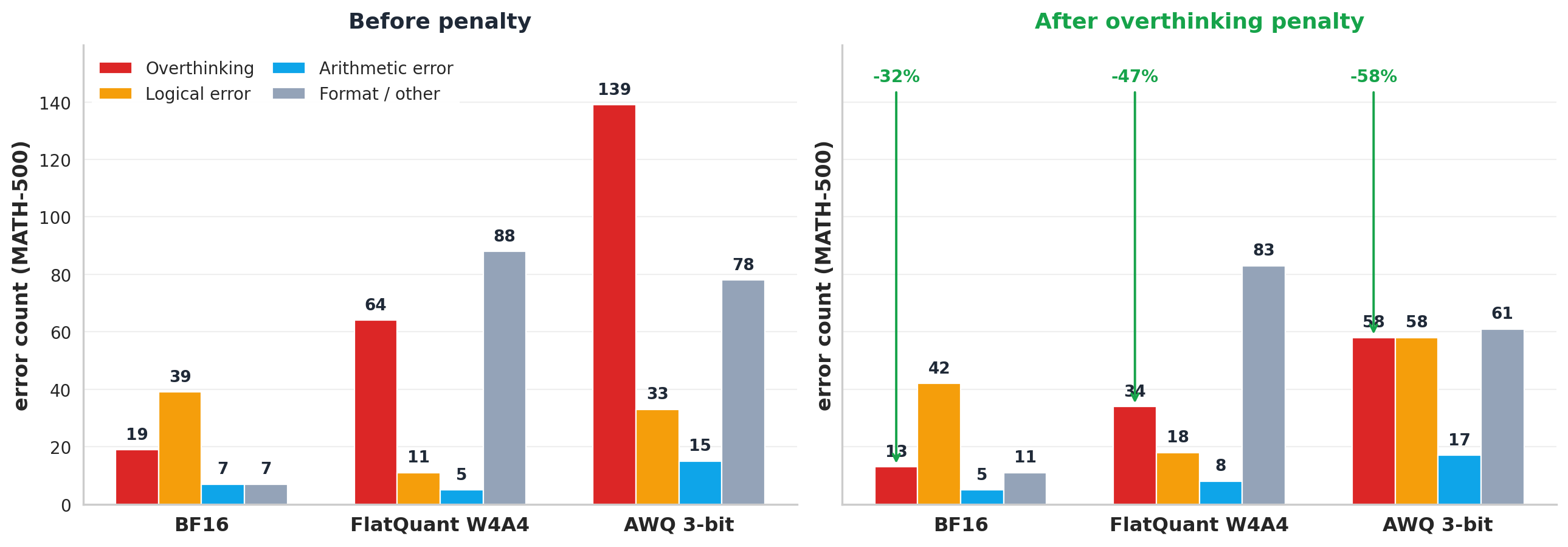
Figure 2. Quantized reasoning models produce longer CoT while achieving lower accuracy. DeepSeek-R1-Distill-Qwen-1.5B on MATH-500. Gray bars: no penalty. Green bars: with the overthinking penalty (best $\lambda$ per configuration). 3 bit AWQ reduces accuracy from 85.6% to 47.0% while increasing the average CoT from 5.2K to 23.4K tokens, a 4.5× increase. The penalty improves accuracy by 14.2 points and reduces CoT length by 45%. Full model and benchmark results are in Section 4 of the paper.
A qualitative example from MATH-500
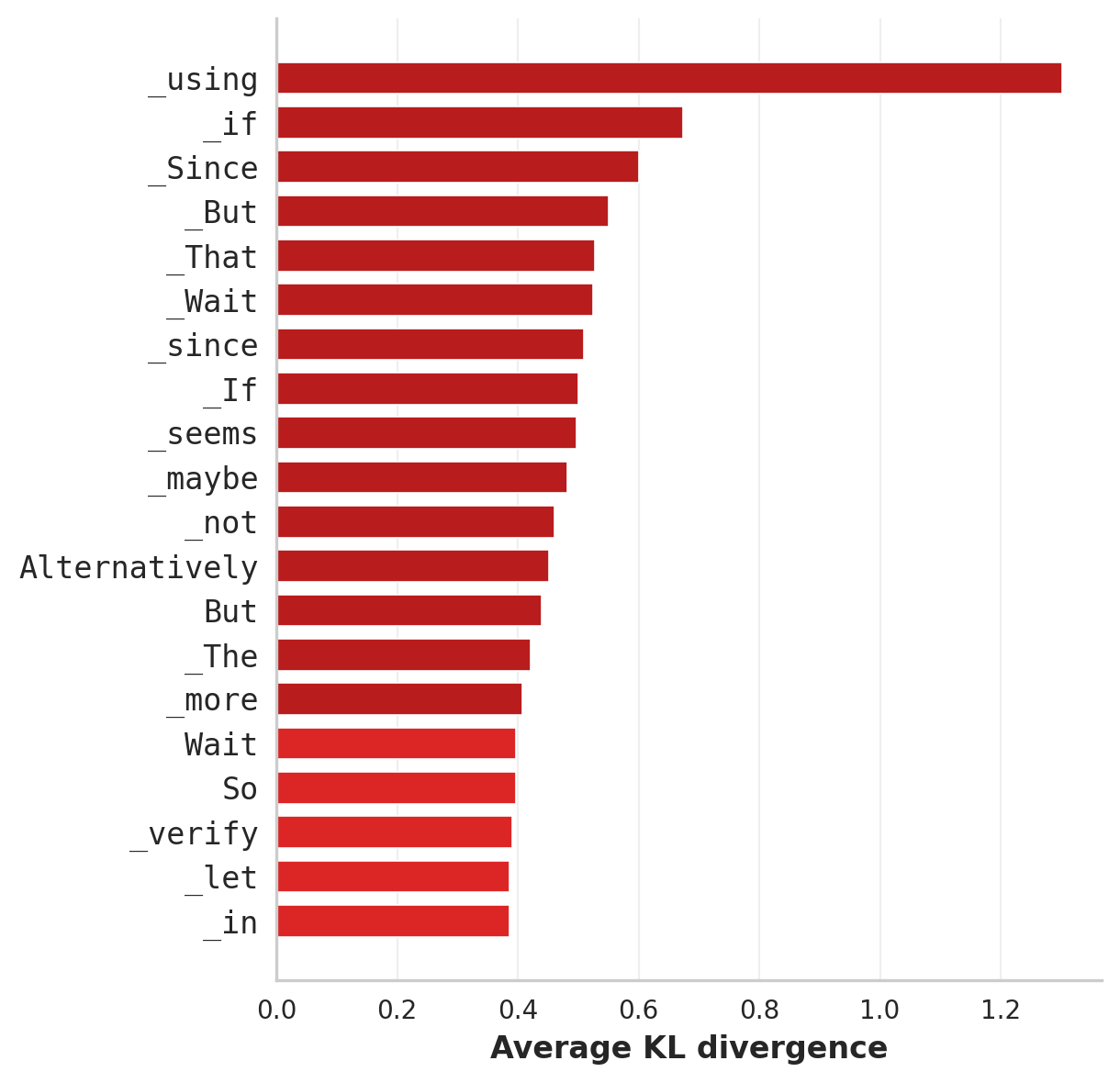
The three generations below illustrate the overthinking failure mode. The BF16 model follows a concise solution. The 3 bit quantized model reaches the correct intermediate result, then samples repeated overthinking markers such as “wait” and “but”, which open alternative reasoning paths and delay termination. The penalized model reduces the probability of those tokens and terminates after reaching the answer. All three reach Answer: 255; only two commit to it.
BF16 (full precision)
= 2^8 - 1
= 256 - 1
Answer: 255
<done>
3 bit AWQ
Answer: 255.
Wait, maybe 11111111 is 8 bits, so 2^8 means 256... no, it's 255.
But what if the phrasing means 2^9-1?
Alternatively, 0s and 1s could be...
Hmm, let me reconsider. 11111111 binary is 128+64+32+16+8+4+2+1 = 255. So actually...
3 bit AWQ + penalty
= 256 - 1
Answer: 255.
Wait, maybe ✂
But what if ✂
Alternatively ✂
<done>
Excerpts from MATH-500 traces. Overthinking markers are shown in red. The penalty subtracts a fixed value from the logits of these tokens at every decoding step, reducing the probability that the model opens a new reasoning branch after it has already reached the answer.
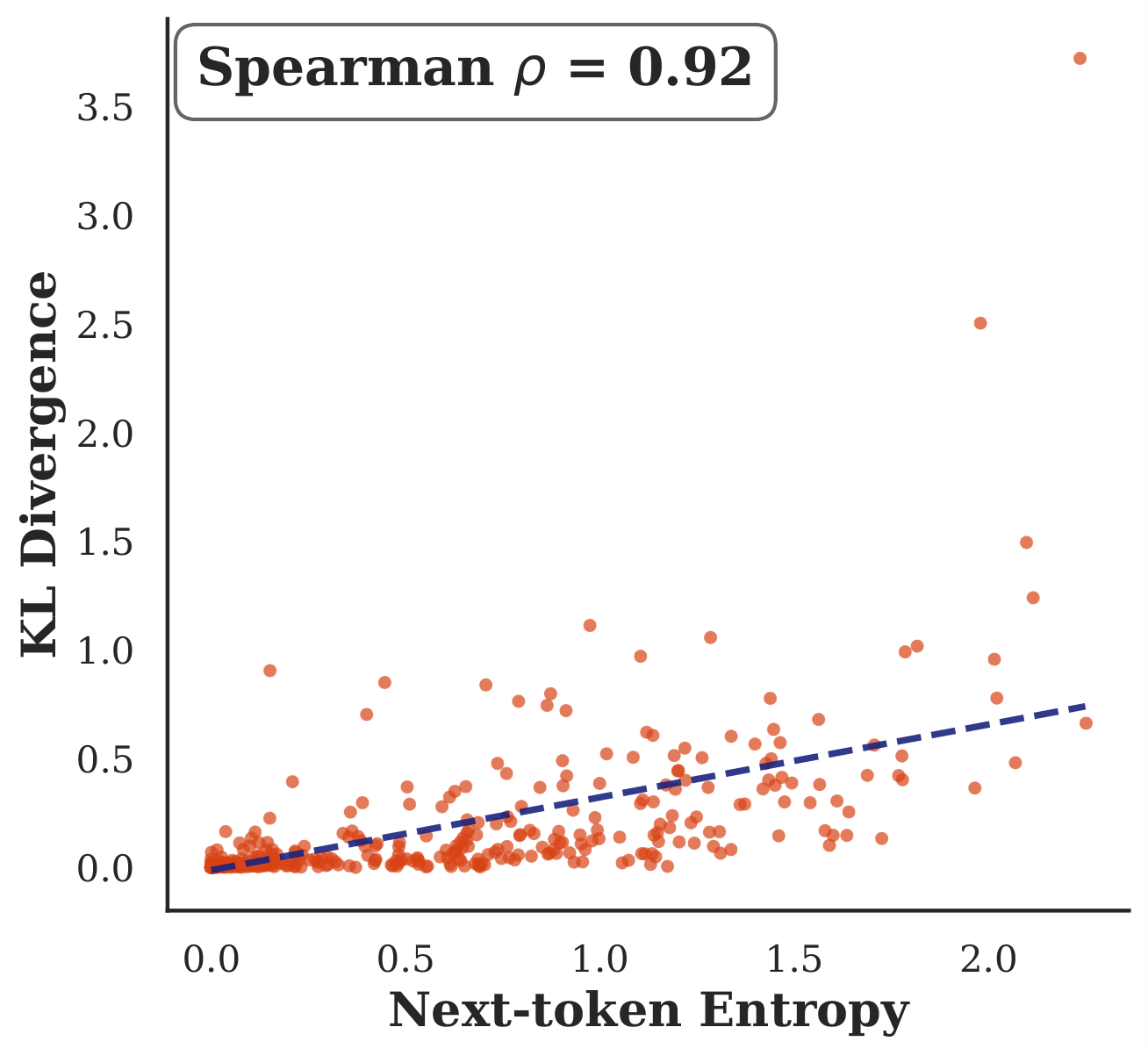
Across all 28 model and quantization pairs, the Spearman correlation between accuracy degradation and CoT length increase is ρ = -0.73. The models that lose the most accuracy are the same ones that produce the longest reasoning traces. PTQ reduces accuracy and increases CoT length at the same time, which suggests that the extra reasoning is part of how quantization hurts accuracy and not just a side effect of it.